Kaggle——作为一款以举办机器学习竞赛、编写和分享代码的平台,正在被越来越多的数据分析爱好者所青睐,这其中更是吸引了数以十万计数据科学家的关注。也正于此,才会被谷歌收入麾下。本人作为一名萌新,本着对机器学习的执著与热爱,在参考多篇文章之后,希望可以为同样喜爱Kaggle的盆友记录写下一点东西,再次感谢那些引路者,正是因为你们,国家在AI这条路上才能越走越远,才会越发强盛。
比赛流程
- 1、赛题背景了解(这会影响第四步)
- 2、数据集下载
- 3、分析数据
- 4、数据处理与特征工程
- 5、模型评估与选择
- 6、结果预测提交
- 7、算法模型优化
上述步骤,以Kaggle竞赛题《Titanic: Machine Learning from Disaster》为样例,预测泰坦尼克号乘客幸存来熟悉机器学习基础知识以及竞赛流程。具体每个步骤所涉及的操作官网均有介绍,相信也更有说服力,这里直接贴代码分析。
背景介绍
耳熟能详的『Jack and Rose』爱情故事延传至今,船长的一句『Lady and kid first!』给原本悲怆黯然的故事增添了敬意,或许这对在当时惊恐万分的人们来说是末日,但时至今日,借助机器之力生成预测模型,是否可以做些预测,让更多的人存活下去,我们可以试试。
数据集
导库 & 加载
import pandas as pd #数据分析库
import numpy as np #科学计算库
from pandas import Series, DataFrame
data_train = pd.read_csv("train.csv")
data_train.columns
有上,打印出训练集中的各特征字段名称
## Data Dictionary
PassengerId ==> 乘客ID
Survived ==> 乘客是否幸存 0=罹难,1=幸存
Pclass ==> 票类 1=一等舱,2=二等舱,3=三等舱
Name ==> 乘客姓名
Sex ==> 乘客性别
Age ==> 乘客年龄
SibSp ==> 兄弟姐妹/配偶数量
Parch ==> 双亲/子女数量
Ticket ==> 票号信息
Fare ==> 船运票价
Cabin ==> 客舱号
Embarked ==> 出发港口
罗列出字典内字段之后,我们需要通过理性思维来筛选出影响乘客幸存的因素再加上船长的『Lady and kid first!』,甚至我们筛选条件可以再宽松一点,老人是否也可以提前乘上救生艇,这个后面再定,所以稍加思考可知
影响因素(暂定)包括:Sex、Pclass、Age
## Exploratory Data Analysis
### 1、处理数据
|
可知:数据集包含891条数据,其中年龄Age有177条缺失,客舱号及出发港口均有不同程度的记录值缺失,这样看还不是很明确,换一下api查看,关于Pandas的DataFrame相关函数,可以参考另一篇文章[传送门](http://tufusi.com/2019/11/17/Pandas%E5%BA%93%E4%B9%8BDataFrame/)
|
打印如下
| | PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare |
| :----: | :----: | :----: | :----: | :----: | :----: | :----: | :----: |
|count|891.000000|891.000000|891.000000|714.000000|891.000000|891.000000|891.000000|
|mean|446.000000|0.383838|2.308642|29.699118|0.523008|0.381594|32.204208|
|std|257.353842|0.486592|0.836071|14.526497|1.102743|0.806057|49.693429|
|min|1.000000|0.000000|1.000000|0.420000|0.000000|0.000000|0.000000|
|25%|223.500000|0.000000|2.000000|NaN|0.000000|0.000000|7.910400|
|50%|446.000000|0.000000|3.000000|NaN|0.000000|0.000000|14.454200|
|75%|668.500000|1.000000|3.000000|NaN|1.000000|0.000000|31.000000|
|max|891.000000|1.000000|3.000000|80.000000|8.000000|6.000000|512.329200|
以上表格才稍微能看:
mean(平均数)得知Survived(存活)率约为38%;
Pclass=一等舱数<Pclass=二/三等舱数;
乘客平均年龄为29岁,最大是80岁
等等...
### 2、特征工程
接着我们用点手段看最直观的图,使用绘图库Matplotlib
|
运行得到绘图
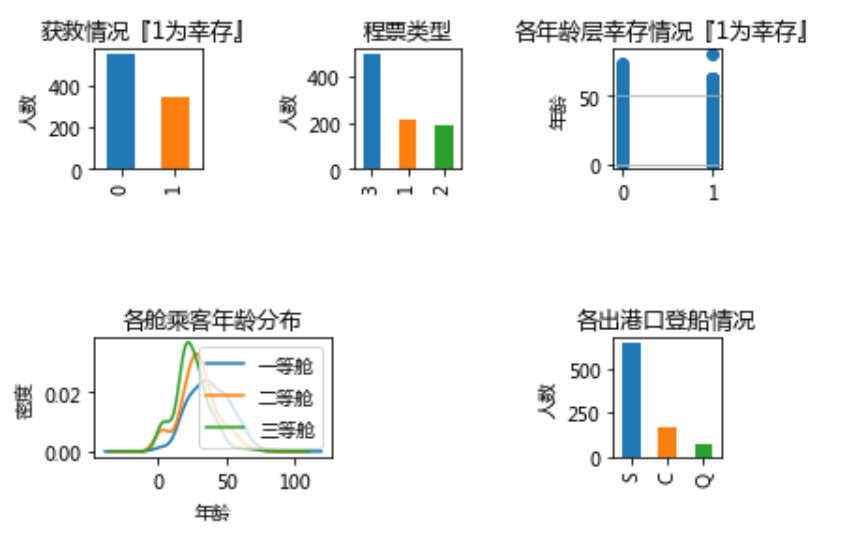
注:以上是合成一张大网格罗列出的绘图,代码运行观看每一张更为直观
从上图种种可看出:
- 大致有300多人获救
- 有一半以上购买三等舱
- 各年龄层获救/罹难均有,分布较广
- 三等舱和二等舱总体趋势相似,并且年龄层占比最多的是在20、30岁左右,一等舱最多是40岁左右乘客
- 出港口人数以S(英国南安普敦(Southampton))最多,其次是C(法国 瑟堡-奥克特维尔(Cherbourg-Octeville)),最后是Q(爱尔兰 昆士敦(Queenstown)),不难理解,人数越多越有可能是出发港口,其他均是途径。
现在我们有一些疑问了:
① 这三百多人获救与购买不同等级舱有无关系?
② 年龄和性别对获救的影响大吗?(毕竟船长发过话)
③ 出港口的不同是不是也会影响乘客获救?
下面验证上面三个问题
|
运行得到绘图
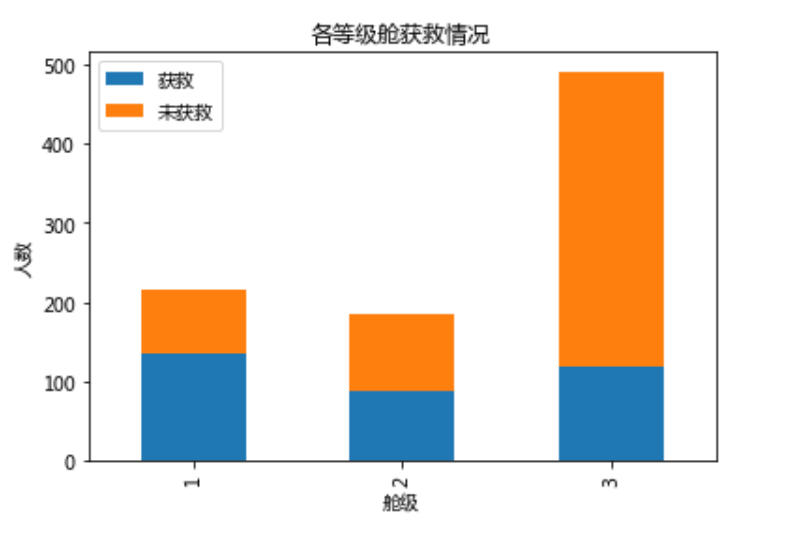
你看可以很明显的看出舱级越高幸存概率越大,这是决定因素之一
在看第二个问题
|
运行
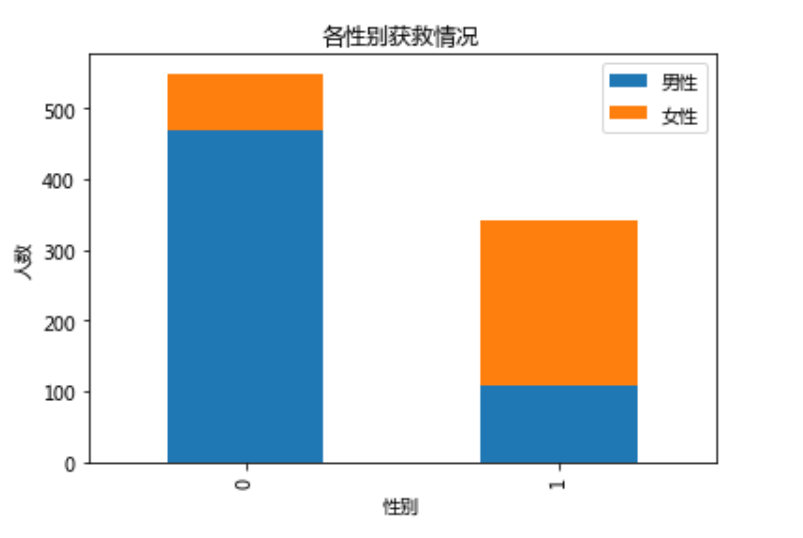
果然女性乘客获救比例比男性大很多,性别无疑也是作为模型中的重要的特征之一
同样年龄(取分割线为30岁,平均岁数)也可以尝试一下,并没有发现什么,但是随着分割的岁数越来越大,可以发现遇难的概率也是越来越大的,这也很符合常识,年迈的虽然会优先对待,但在那种恶劣处境下,毕竟求生本领还是很弱的。
看最后一个问题
|
运行
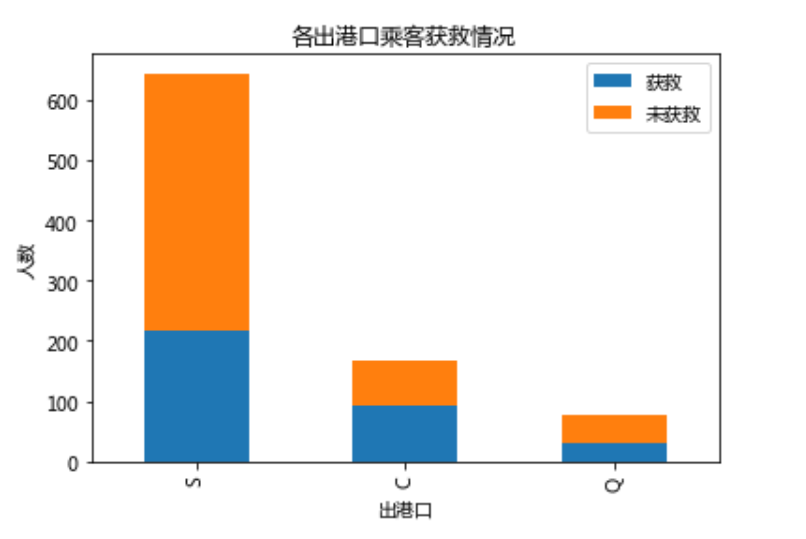
不怎么看的出来, 如果要解释从出发港口出发的乘客获救的几率大一点似乎也没多大说服力。暂时不管
既然这样,那条件继续细分
|
运行如下
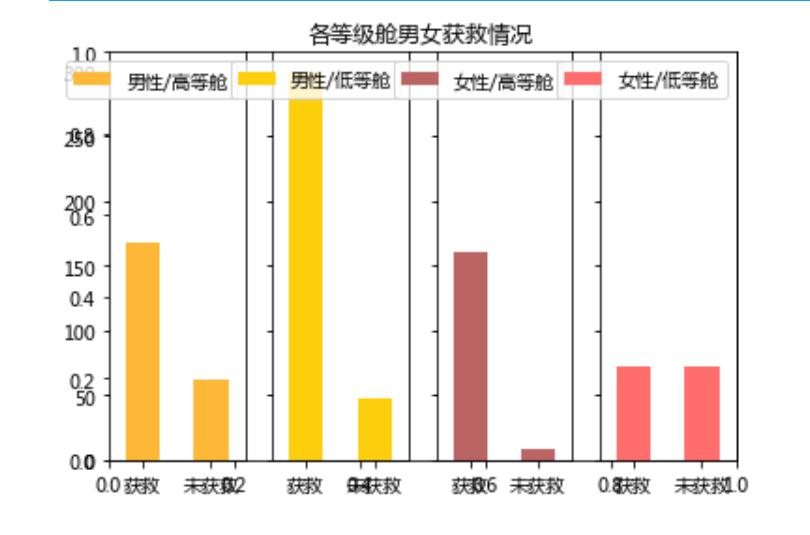
继续
|
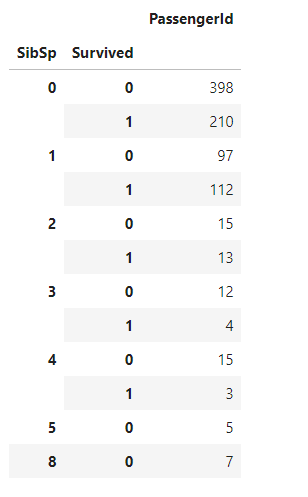
|
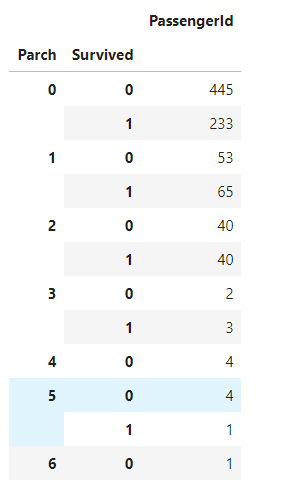
还是看不出必然关系,那就先清洗一下数据,对缺失值做些处理,先从Cabin、Age缺失最严重却又是重要特征入手
### 3、缺失数据处理(清理数据)
**通常遇到缺失值,最常见的处理方式有这些**
- 1.如果缺失的样本字段值占比很多,一般都需要舍去,以防形成噪声影响结果
- 2.如果缺失样本占比适中,并且该属性是非连续性的特征属性,即分类属性的话,可引入NaN作为新类别特征
- 3.如果缺失样本占比适中,并且该属性是连续性的特征属性,可以考虑步长step,并将其离散化分布
- 4.如果缺失样本占比极少,可考虑手动加入拟合数据
可以尝试[随机森林](https://scikit-learn.org/stable/modules/ensemble.html#forest),一种集成学习模型,训练多个决策树,考虑多个结果做预测,这里使用[sklearn](https://scikit-learn.org/stable)库中的随机森林:
**它的随机性体现在**
- 从原来的训练数据集随机(带放回样本)取一个子级作为森林中某个决策树的训练数据集
- 每一次选择分叉的特征时,限定为在随机选择的特征的子级中寻找一个特征
**它的优势体现在**
- 消除决策树容易过拟合的缺点
- 减小预测的方差:预测值不会因为训练数据小变化而发生剧烈变化
这里用scikit-learn 的Random-forest拟合缺失的年龄数据
**拟合缺失数据**
|
运行得到如下(只截取部分)
**独热编码**
|
得到
**对幅度过大特征属性值进行归一化 加速逻辑回归收敛**
|
得到
### 4、建模
**取出特征字段 模型建模**
|
## 模型优化:从 Baseline 到 Top 10%
### 5、特征工程深度挖掘
初始得分 0.7655 只是 baseline。进一步深入特征工程可以挖掘以下方向:
**(1)Name 特征的提取——乘客称谓(Title)**
姓名中的称谓(Mr/Mrs/Miss/Master/Dr 等)隐含了年龄、婚姻状态和社会地位信息,与幸存率高度相关:
```python
# 提取称谓
data_train['Title'] = data_train.Name.str.extract(' ([A-Za-z]+)\.', expand=False)
# 将稀少称谓归并
title_mapping = {
'Mr': 'Mr', 'Mrs': 'Mrs', 'Miss': 'Miss', 'Master': 'Master',
'Dr': 'Officer', 'Rev': 'Officer', 'Col': 'Officer',
'Major': 'Officer', 'Capt': 'Officer', 'Countess': 'Royalty',
'Lady': 'Royalty', 'Sir': 'Royalty', 'Don': 'Royalty',
'Dona': 'Royalty', 'Jonkheer': 'Royalty', 'Mme': 'Mrs',
'Mlle': 'Miss', 'Ms': 'Miss'
}
data_train['Title'] = data_train['Title'].map(title_mapping)
|
data_train['FamilySize'] = data_train['SibSp'] + data_train['Parch'] + 1
data_train['IsAlone'] = (data_train['FamilySize'] == 1).astype(int)
data_train['FamilyGroup'] = pd.cut(data_train['FamilySize'],
bins=[0, 1, 4, 11], labels=['Solo', 'Small', 'Large'])
|
data_train['Deck'] = data_train['Cabin'].apply(
lambda x: str(x)[0] if pd.notnull(x) else 'U')
|
ticket_counts = data_train.groupby('Ticket')['PassengerId'].transform('count')
data_train['TicketGroupSize'] = ticket_counts
|
data_train['AgeBand'] = pd.cut(data_train['Age'],
bins=[0, 12, 18, 30, 50, 80],
labels=['Child', 'Teen', 'Adult', 'MiddleAge', 'Senior'])
|
data_train['FareBand'] = pd.qcut(data_train['Fare'], 4,
labels=['Low', 'Medium', 'High', 'VeryHigh'])
data_train['IsFreeTicket'] = (data_train['Fare'] == 0).astype(int)
|
from sklearn.ensemble import VotingClassifier, RandomForestClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
rf = RandomForestClassifier(n_estimators=100, random_state=42)
svc = SVC(kernel='rbf', probability=True, random_state=42)
lr = LogisticRegression(C=1.0, penalty='l1', solver='liblinear')
voting_clf = VotingClassifier(
estimators=[('rf', rf), ('svc', svc), ('lr', lr)],
voting='soft')
voting_clf.fit(X, y)
|
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import GradientBoostingClassifier
base_models = [
('rf', RandomForestClassifier(n_estimators=200)),
('gbdt', GradientBoostingClassifier(n_estimators=100)),
('svc', SVC(kernel='rbf', probability=True)),
]
meta_model = LogisticRegression()
|
import xgboost as xgb
xgb_clf = xgb.XGBClassifier(
n_estimators=300, max_depth=4, learning_rate=0.01,
subsample=0.8, colsample_bytree=0.8, reg_alpha=0.1
)
xgb_clf.fit(X, y)
|
from sklearn.model_selection import cross_val_score, StratifiedKFold
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
scores = cross_val_score(model, X, y, cv=skf, scoring='accuracy')
print(f'CV Mean: {scores.mean():.4f} (±{scores.std():.4f})')
|
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [3, 4, 5, None],
'min_samples_split': [2, 5, 10]
}
grid = GridSearchCV(RandomForestClassifier(), param_grid,
cv=5, scoring='accuracy', n_jobs=-1)
grid.fit(X, y)
print(f'Best params: {grid.best_params_}')
print(f'Best CV score: {grid.best_score_:.4f}')
|



